










【ネットアシストニュースレター | Vol.5 】
AWSの大規模障害から考える AWSのSLAとは?
2021年9月2日(木)AWSの東京リージョンで大規模な障害が発生しました。金融機関や証券会社などのシステムに影響が発生し、テレビやネットでも大きく報道されていたので、皆様も記憶に新しいかと思います。ネットアシストにもAWSをご利用中のお客様から多数お問合せがございましたので、今回はこちらの障害についての概要と、ここ数年で東京リージョンで発生した大規模障害についての情報も共有させて頂きます。
9月2日の障害について
今回の障害は、AWSユーザの多くが利用しているであろう「EC2」や「RDS」などに関わるサービスの障害ではなく「Direct Connect」を利用しているユーザ限定でサービスに影響を及ぼすものでした。
「AWS Direct Connect」とは、AWSのネットワークサービスの一つで、オンプレ環境等とAWS環境とをインターネットを経由せず、専用線で接続することが可能となります。
今回の障害の原因はDirect Connectのロケーションから、東京リージョンのネットワーク間で利用しているネットワークデバイスの一部に、障害が発生したことが原因でした。障害発生が午前7時半頃、完全に復旧したのが午後1時42分頃のようなので 半日程度、システム障害が発生していたことになります。
前述のとおり金融機関や証券会社のシステムが、半日も突如停止してしまう状況に陥るとなると、機会損失がどれほどのものだったのかと想像してしまいます・・・。
AWS東京リージョンで直近であった障害とは?
2021年2月20日
東京リージョンのデータセンターの一部区画で室温が上昇したことにより、EC2インスタンスがダウン。EC2にアタッチするEBSにも一部影響が発生しました。
原因は、データセンター内の冷却設備の不良によるもので、19日夜間から20日の早朝にかけて、コインチェックや気象庁のWebサイトも一時閲覧できなくなった模様。
2019年8月23日にも同様の障害が発生しており、EC2インスタンスが停止し、EBSのパフォーマンスにも影響が及んでいます。
2020年10月22日
東京リージョンのデータセンターで、一部のEC2のネットワーク障害が発生。同じタイミングで、別のデータセンターのEBSでパフォーマンスが低下しました。ネットワークの接続性に問題があったようですが、問題についての詳細な内容はAWSから発表されていません。
SLAとは
SLAはService Level Agreementの略でサービス水準合意やサービスレベル契約などと訳されます。
これは事業者とユーザーの合意事項で、SLA対象サービスの月間稼働率が、規定の稼働率に満たなかった場合は返金・減額などの対応が行われます。
有名なところではAWS EC2の99.99%、Amazon RDSの99.95%などがあります。100%に近い数字でこれだけ9が並んでいるとまったく止まらないイメージを持ちますが停止しても良い時間を1カ月で換算をすると下記の表のようになります。
| SLA | 停止時間 |
| 99% | 430分(7.2時間) |
| 99.9% | 43分 |
| 99.95% | 21分 |
| 99.99% | 4.3分 |
| 99.999% | 0.43分(25.8秒) |
予想していたよりも止まる時間が長いと感じる方が多いのではないでしょうか。またSLAの対象となるためには基本的にAWSのベストプラクティスに従っている必要があります。先ほどのEC2の99.99%もMultiAZの場合(2台以上)のみに適用されます。1台だけで稼働しているシングルインスタンスの場合は90%となり停止時間は4,300分(72時間)/月になります。
1日に2.4時間・月に3日サービス停止する可能性があると思うとぞっとします。
さらにSLAの返金対象は障害があったサービスのみです。 EC2 の障害であれば EC2 分のみ。 RDS の障害であれば RDS 分のみです。構成にもよりますが、EC2(1台)+RDS+S3で運用しているECサイトでEC2が3日以上停止し、サイトもダウンしても対象はEC2の利用料のみです。
当たり前ですが、サイト停止期間中の損害については何の保証もされません・・・
AWSを筆頭にクラウドサーバは落ちないイメージを持たれることがありますが、運用ポリシー上、許容されるダウンタイムに合わせて可用性を考慮した構成が必要になります。
IDCFクラウドでのDR事例のご紹介
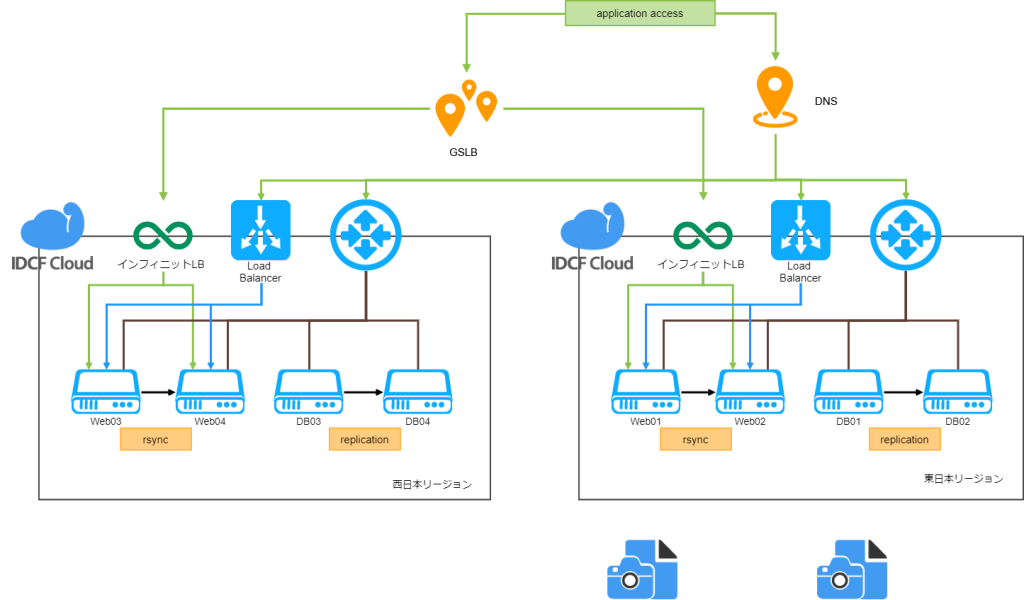
DR冗長構成でサーバーを構築させていただきました。この案件では、IDCFクラウドで東日本リージョンと西日本リージョンで構築しています。東日本リージョンがアクティブ、西日本リージョンがホットスタンバイの構成です。仮に大規模災害などにより東日本リージョンが機能しなくなった場合は、GSLBにより西日本リージョンに振り分けられます。
西日本リージョンに振り分けられた後は、ネットアシストで西日本リージョンのDB03のRead Only を解除して、西日本リージョンをアクティブサーバーとして稼働させます。また、その間に機能しなくなった東日本リージョンを修復して、新しいホットスタンバイ環境を構築する事になります。
構成のポイントとして各リージョン内でも冗長化しているため、何らかの問題でWebサーバーやDBサーバーに問題が起きても、リージョンを切り替えることなくサービスの継続が可能です。その上で、リージョン単位の大規模障害にも備える構成になっています。
現時点で落ちないサーバーは存在しないのが実情です。そのため、同一リージョン内での冗長構成化、さらには複数リージョンでのDR冗長構成化など、できるだけダウンタイムを短くする構成とその運用が求められるケースが増加しています。
今回はIDCFクラウドでのDR冗長構成をご紹介させていただきましたが、IDCFクラウド以外でも多数のDR冗長構成を取り扱っていますので、お気軽にご相談ください。